Why AI Agents Forget You.
A deep dive into why AI agents can't remember you across sessions, and the five memory architectures researchers are building to fix that.

It's been some time since I dove deep into agentic AI and its workings. Through all that, one theme comes up over and over - memory. Not in the abstract, philosophical sense of the term. Practical, concrete memory that lets you actually remember important constraints and preferences over multiple conversations.
The agent has just forgotten something you told it three sessions ago. Again. It has greeted you like a complete stranger. And here's the really annoying part, you weren't talking about something obscure that a developer on your team would probably forget in a week. You were talking about something critical; the fact that you deprecated a certain API and it should be avoided. Yet the next day the agent happily suggested that API to you.
This is why memory in agentic agents is so essential. And this is why I want to dig deep into what's actually going on under the hood.
The 'Amnesia' Problem
The core issue is that virtually all language models are stateless, i.e., lack memory of any form. Every conversation starts from square zero. Every interaction, regardless of its importance and context, is thrown away once it's processed. You ask, the model gives an answer, and everything else is forgotten immediately after. Great for a chatbot. Terrible for something you'd trust with your calendar, your development projects, and your personal preferences.
Five Memory Types, Five Solutions
Having read at least a dozen papers on the topic, I came to the following conclusion: there are many ways to handle memory, but they all differ in application domains. Rather than a single monolithic solution, I found a set of different methods. Each addresses a specific subset of problems related to memory.
01 - Working Memory: Whatever Fits in the Context Window
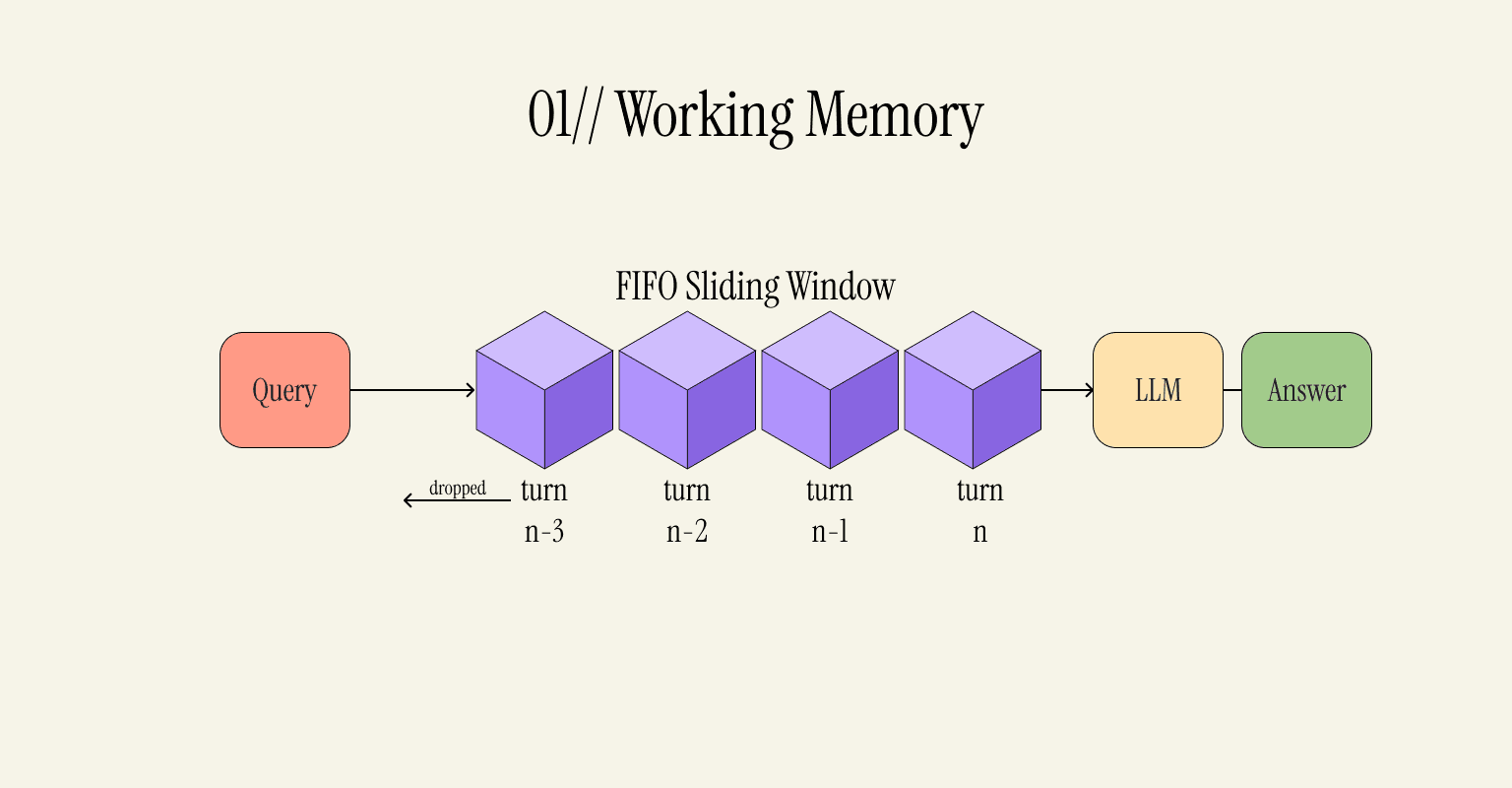
This is probably the basic form of memory in AI agents. You can consider it the default memory strategy, especially when building consumer chatbots. It involves holding only recent conversation history in the active context window and removing old messages using FIFO (First In First Out). So, when a request arrives, the context window is filled with history and a new message. Everything gets processed.
It's simple and efficient. It's easy to inspect the contents of the context window at any time; everything's in plain sight. But that's also the problem with this method; you only get the last few messages in the conversation history, and everything else is gone forever. This is the main reason why most chatbots introduce themselves anew every time.
I ran into this myself while building an AI mailbox assistant called Automail. The agent was great at reasoning and search during one session. Across sessions? Absolutely zero memory. It had absolutely no idea about what mails were delivered 2 days ago.
02 - Episodic Memory: Relevant Information Retrievable On Demand
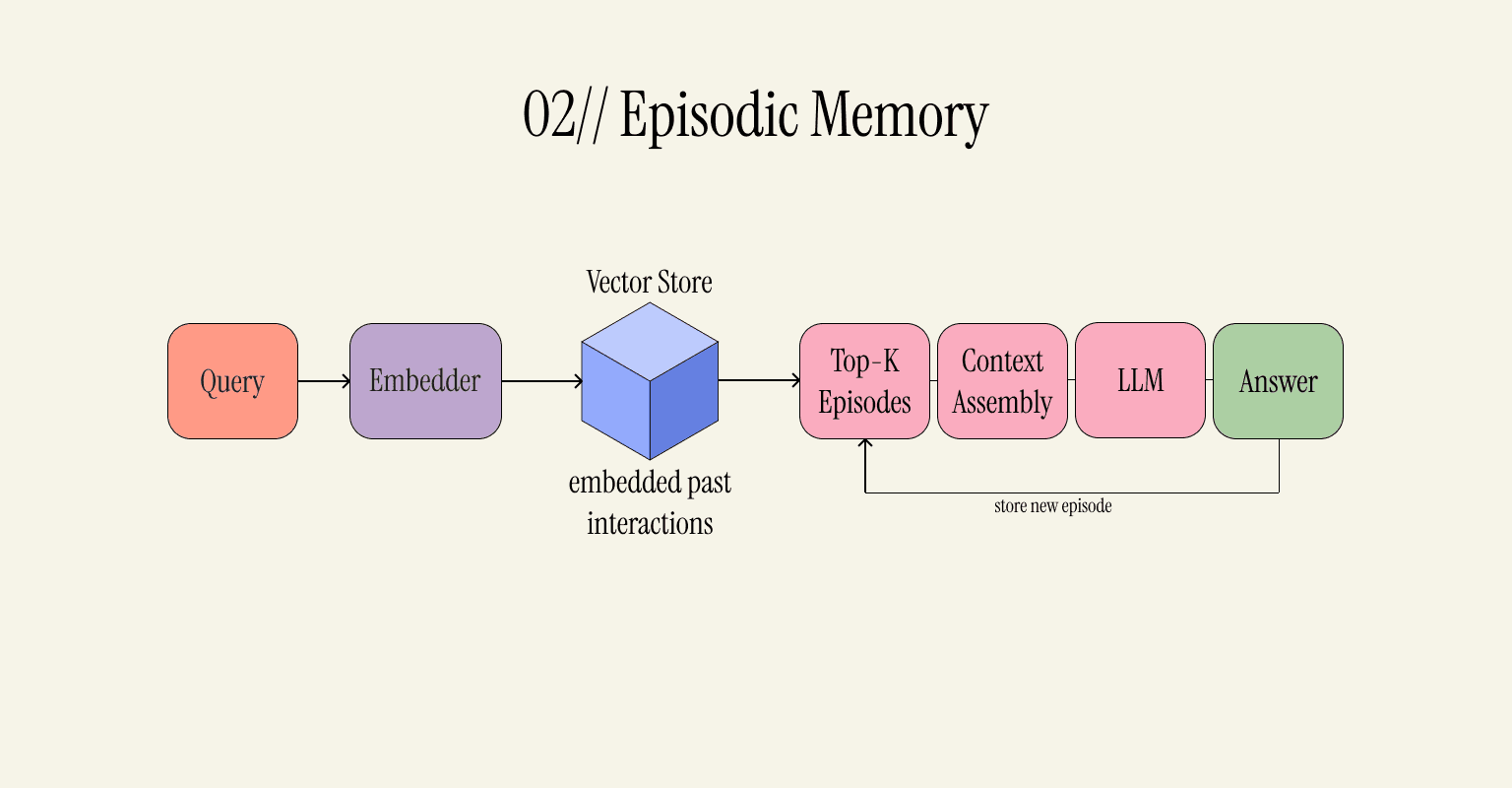
This approach solves the biggest problem with working memory: there's memory beyond the context window. Conversations are stored in a vector-based format in the vector store. Instead of dropping old episodes and keeping the latest messages, you're embedding the new episodes and appending them to memory. The vector representation holds some semantic meaning, so you can search the store for related episodes.
Now, whenever you submit a new message, the request gets embedded into the store. The system looks for the semantically most relevant episodes in history and appends those to the message you sent. The agent receives all of this as context for answering. After each session, new episodes are stored.
What you get in return? Better consistency and better long-term memory. As a result, you actually train the assistant to remember important information for weeks or even months.
What's the limitation? Vector similarity finds what's related, not what's important
Let me give you an example to this failure. Imagine you have a travel assistant. It knows you prefer window seats and always fly business class. You ask it to book the next available flight to Singapore. It finds one, picks a window seat in business, done. Except you mentioned offhandedly two weeks ago that your passport expires next month and you haven't renewed it yet. A system with real memory holds the booking, flags the passport issue first. A system without it books you a flight you can't board.
That's the gap between a system that retrieves and a system that actually reasons.
03 - Semantic Memory: Things That You Know
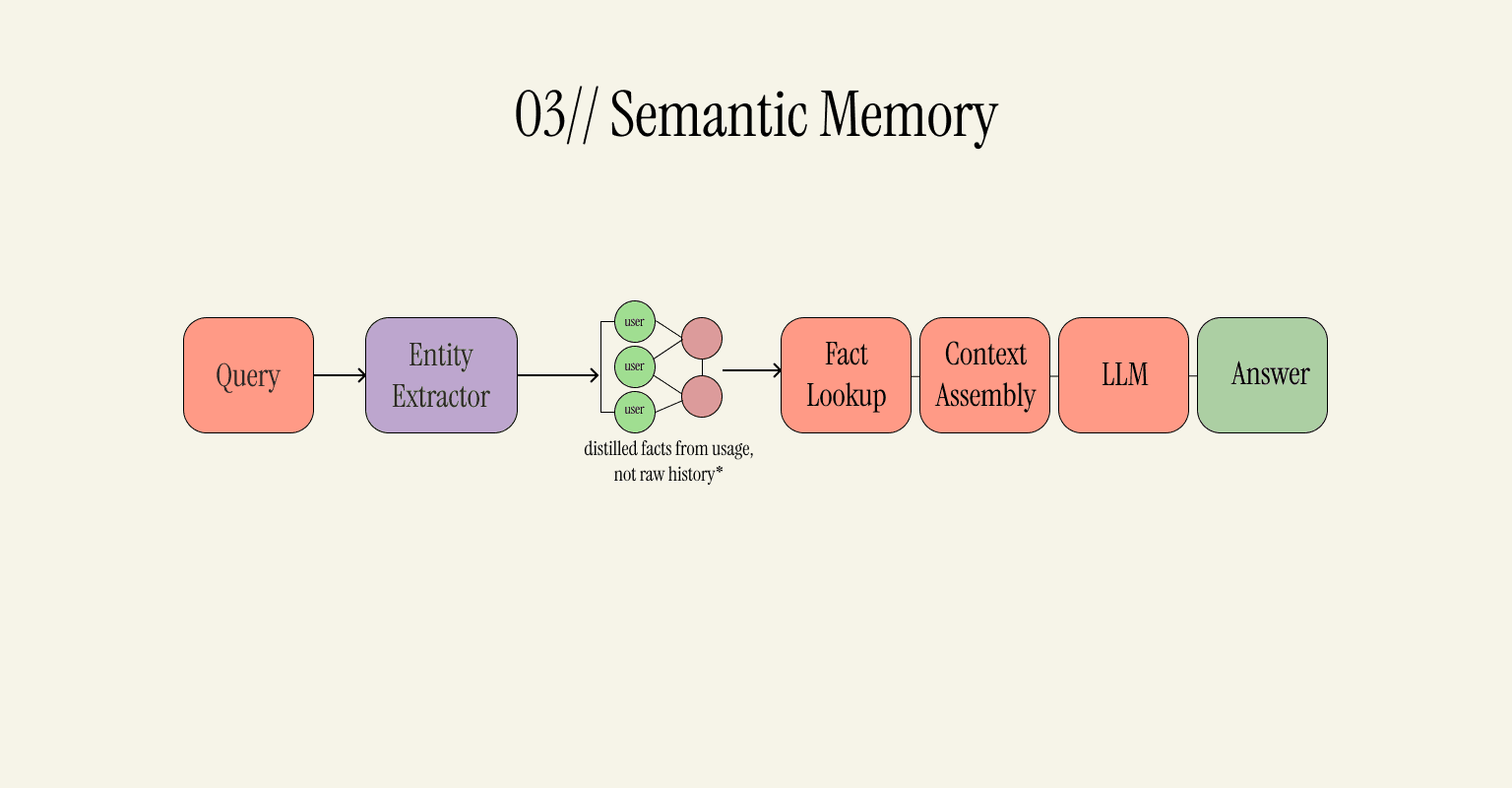
This memory type is concerned with actual facts. Instead of storing information as free-form conversations (like episodic memory), this one focuses on extracting entities from conversations and storing them in a knowledge graph. For instance, it can remember that you prefer dark mode over light mode, that you work in software, and that your time zone is IST.
So, when a request comes in, it searches the knowledge graph for all the relevant facts and combines them in the context before forwarding it to the agent. The advantage? Facts are always correct, unlike episodic memory that has semantic gaps.
The trade-off, however, is real. First off, extraction algorithms make mistakes. So, you get false information in your memory store. And there's nothing to check it against. This makes it difficult to trace errors.
04 - Procedural Memory: How to Accomplish a Task, Memorized
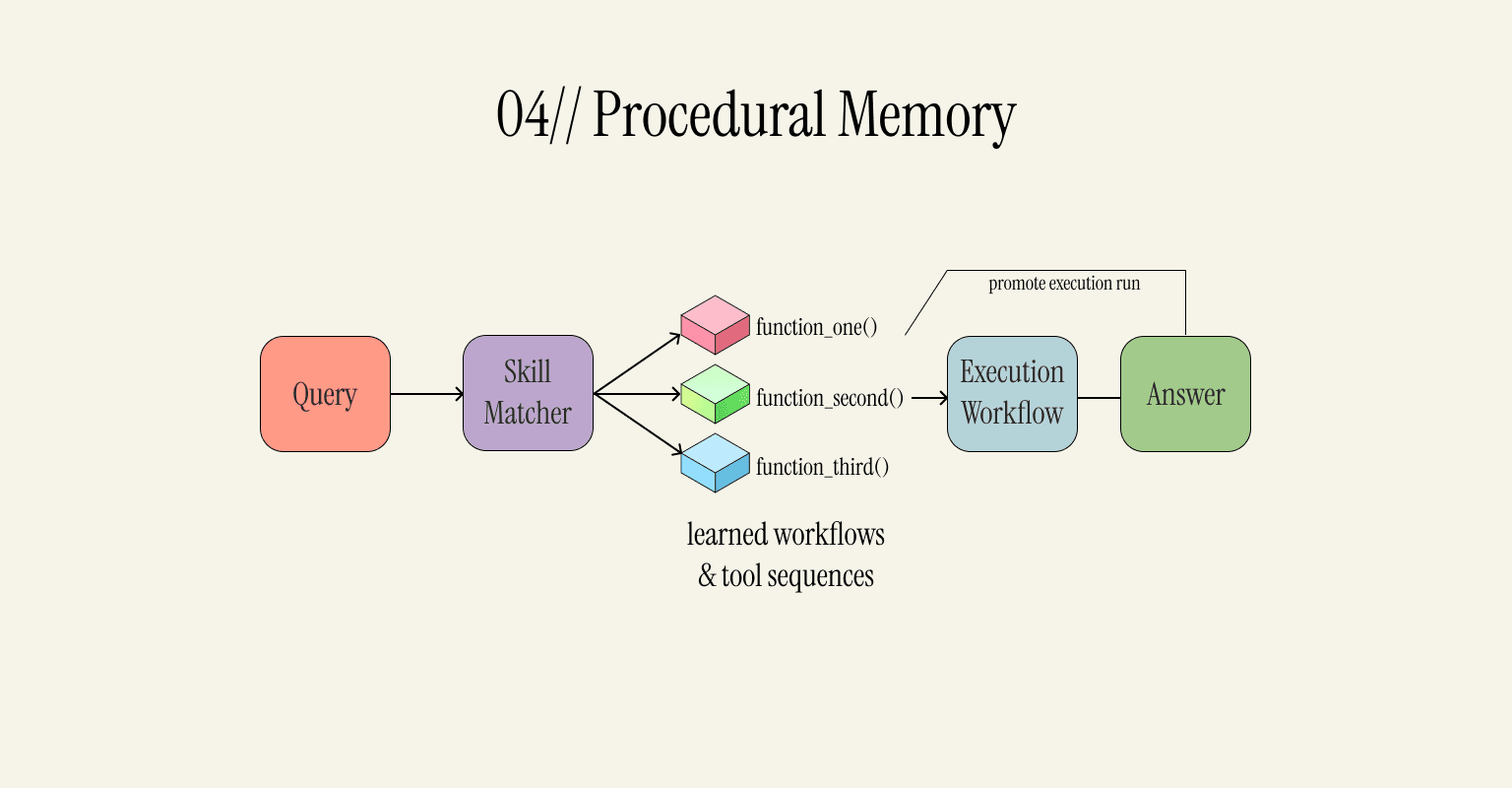
This type is somewhat unique since it addresses a slightly different task; learning procedural skills. Instead of storing conversation snippets and facts, this memory type contains skills that allow the agent to complete tasks. Each skill has metadata that describes what it accomplishes (a natural language description of the function). A skill matcher is responsible for finding the skill that can complete a task. Then, it is executed.
With time, you can see skills getting upgraded. The more the agent uses a particular skill, the more reliable it becomes. So, instead of figuring out how to solve a problem from scratch every time, you teach your agent how to solve it.
The best real example for this is Voyager, a learning agent in Minecraft that continuously explores the world, acquires diverse skills, and makes novel discoveries without human intervention. Every time Voyager successfully completes something like mining a specific ore, crafting a tool or navigating a cave - the code that accomplished it got stored as a named, reusable skill. Next time a similar task came up, the agent retrieved that skill instead of generating new code from scratch. Failed attempts did not make the cut. Only verified, working routines got promoted into the library.
That's the core idea behind procedural memory. The agent isn't just remembering facts. It's accumulating capability.
05 - Hierarchical Memory: Hot, Warm, and Cold Memories; Paged Memory Management
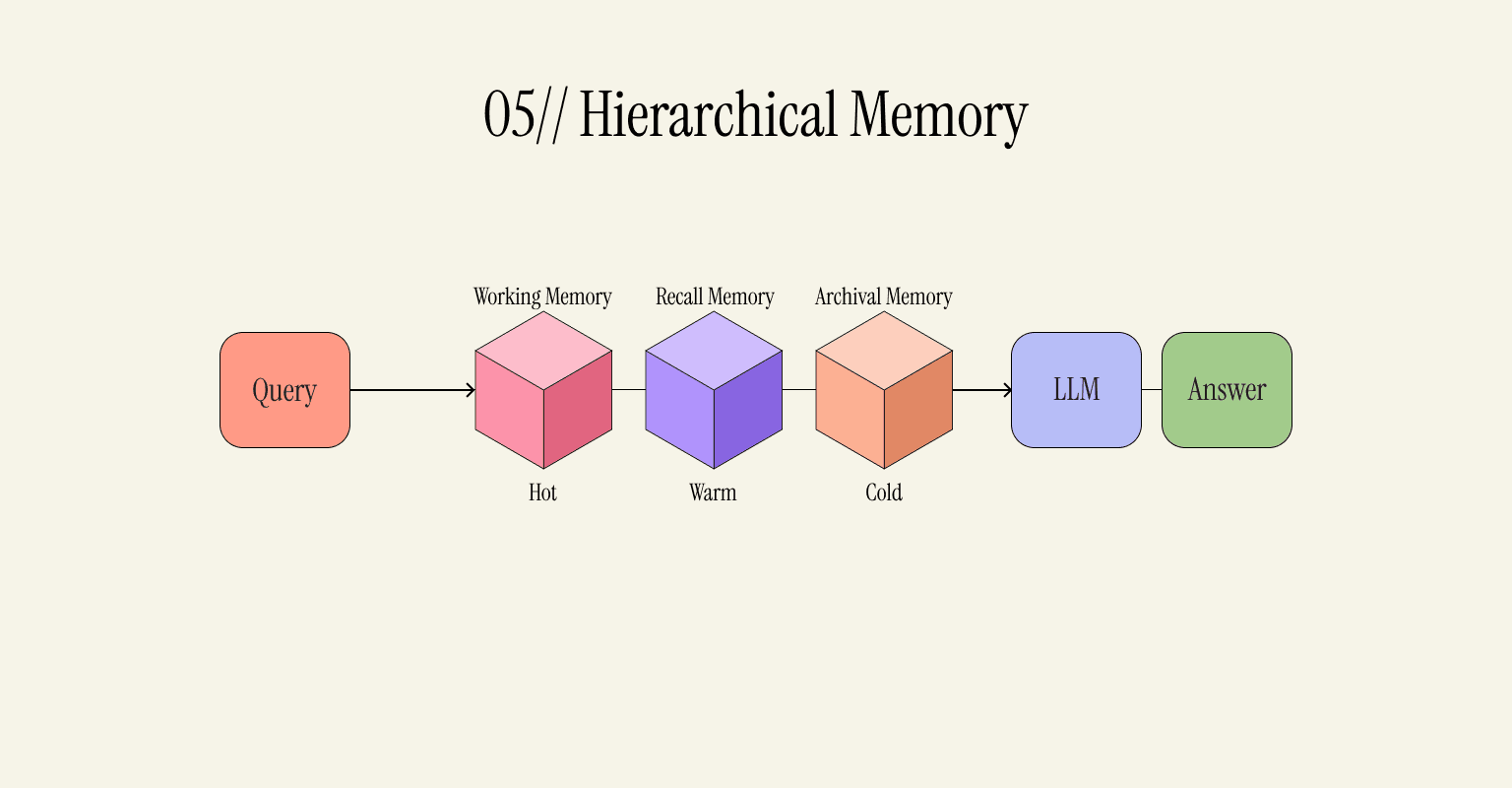
This is one of the more sophisticated approaches to handling memory. It takes inspiration from computer architecture and employs the idea of tiered storage, where information is paged depending on its accessibility.
The system maintains three types of memories; hot, warm, and cold. Hot memory contains the live conversation history. Warm memory stores recently used history. Cold memory holds all remaining history. Access is performed from top to bottom; hot memory first, followed by warm and cold memory.
Whenever information is needed, it's fetched from one of these three memory types and placed in hot memory. After the interaction finishes, warm and cold memories are purged.
In this regard, this approach is quite elegant since all information is always accessible. However, the key to its effectiveness lies in managing evictions from the hot window. It's a challenging task because eviction needs to occur instantly during interaction.
How These Types Actually Complement One Another
Most agents don't use memory in isolation. Instead, multiple types can be integrated into a single architecture. EverMemOS is currently the leading framework of this sort. It features all five memory types:
- Working memory: live context window.
- Episodic memory: via MemCell formation and vector-indexed storage.
- Semantic memory: via incremental clustering and building of stable user profiles.
- Procedural memory: via time-bounded plans with validity windows.
- Hierarchical memory: through hot/warm/cold paging used by its retrieval module.
The advantages of such architecture aren't just theoretical. EverMemOS shows 9.2% improvement on LoCoMo benchmark and 6.7% on LongMemEval. Both of these improvements are made while consuming about half the number of tokens compared to comparable architectures. That's the difference efficient curation of memories can make.
What Actually Goes Wrong When Implementing Memory in Agentic AI
It's time to move to actual practical challenges with memory. I'm sure that you will agree that this part is missing in most blog posts. Let me walk you through these challenges now.
One of the first issues with memory management is known as summarization drift. The problem with the vector store is that information gets aggregated. This means that, with every iteration, the agent forgets some lower-freq stuff. For example, the constraint "never write to the production database" may slip through the cracks and be forgotten.
Another issue is called self-reinforcement error. Suppose that the agent decided to avoid using a specific API because it deemed this API "unstable". This decision was based on the last few iterations only, and it wasn't necessarily correct. However, by avoiding using this API, the agent didn't have an opportunity to collect data about it and adjust its decision. This creates a self-reinforcing error in decision-making.
Finally, increasing the window size won't help you as much as you think. It might seem tempting to increase the context size to accommodate all interactions, but it might be problematic. In fact, researchers named this issue "lost-in-the-middle problem", and for good reason. Modern models have a hard time paying attention to everything in long contexts. Larger contexts increase the latency, raise costs, and cause "context rot"; where models lose focus, make mistakes and forget critical instructions.
How We're Currently Measuring Agentic Agents' Memory Capabilities
We can see significant progress in this area recently. Instead of trying to measure memory capabilities through ability to recall specific facts, people now try to evaluate memory through real use cases. This brings us closer to real-world situations.
There are quite a few of these evaluation techniques. LoCoMo is a test for measuring memory retention across multiple sessions. LongMemEval checks an agent's ability to interact through memory. PersonaMem-v2 evaluates the capability to build implicit user profiles through behavioral patterns (instead of just memorizing explicitly said facts). MemoryArena evaluates agent's ability to coordinate information across multiple domains.
Interestingly, models that scored maximum in long-term memory benchmark still failed MemoryArena and showed ~40-60% accuracy. It appears that there is a distinct difference between retaining memory and coordinating information from multiple domains.
Future Directions for Memory Research in Agentic Agents
This is my personal vision, but I believe that memory systems will become increasingly more causally-grounded. The idea is that memory isn't supposed to simply retrieve something. What it's actually supposed to do is explain the current situation. This means shifting from the current approach of semantic retrieval to causally-grounded retrieval.
Another thing that should get explored, learned forgetting. All these memory systems focus on what to remember and how to do it efficiently. There's almost no discussion of when and what to forget.